Artificiell intelligens och maskininlärning inom cybersäkerhet
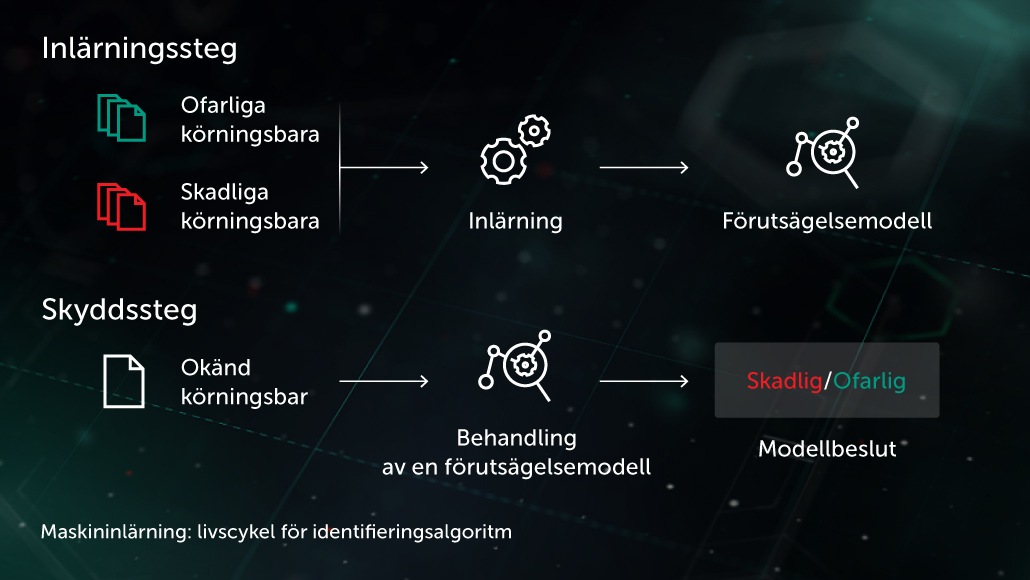
Arthur Samuel, en pionjär inom artificiell intelligens, har beskrivit AI som en samling metoder och tekniker som ”ger datorerna möjlighet att lära sig utan att uttryckligen programmeras”. I ett särskilt fall av övervakad inlärning för anti-malware kan uppgiften formuleras på följande sätt: med en uppsättning objektfunktioner \( X \) och motsvarande objektetiketter \( Y \) som indata, skapa en modell som kommer att producera rätt etiketter \( Y' \) för tidigare osedda testobjekt \( X' \). \( X \) kan vara några funktioner som representerar filinnehåll eller beteende (filstatistik, lista över använda API-funktioner etc.) och etiketter \( Y \) kan helt enkelt vara ”skadlig kod” eller ”godartad” (i mer komplexa fall kan vi vara intresserade av en detaljerad klassificering som virus, trojanhämtare, annonsprogram osv.). Fokus vid oövervakad inlärning ligger på att identifiera dolda datastrukturer som grupper med liknande objekt eller snarlika funktioner.
Tillvägagångssätten för AI, exempelvis ML, i Kasperskys senaste säkerhetslösningar på flera nivåer används i alla faser av identifieringsprocessen, från skalbara klustermetoder vid förbearbetning av inkommande filströmningar till infrastrukturen i robusta, kompakta neurala och djupgående nätverksmodeller för beteendeidentifiering som kan användas direkt i användarens datorer. Dessa tekniker är utformade för att uppfylla flera viktiga krav för verkliga cybersäkerhetsapplikationer, inklusive en extremt låg andel falska positiva resultat, modellernas tolkningsbarhet och ståndaktighet mot angripare.
Nu ska vi gå igenom de viktigaste ML-baserade teknikerna som används i Kasperskys klientsäkerhetsprodukter:
Beslutsträdsstrukturer
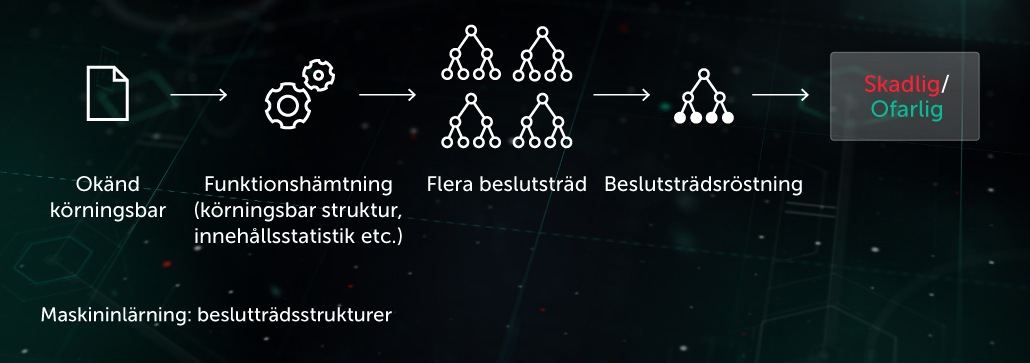
I detta tillvägagångssätt har den förutsägande modellen formen av en uppsättning beslutsträd (t.ex. slumpmässig skog eller gradientförstärkta träd). Varje trädnod som saknar löv innehåller en fråga angående filfunktioner medan lövnoderna innehåller det slutgiltiga trädbeslutet för objektet. Under testfasen avancerar modellen genom trädstrukturen genom att besvara nodfrågorna relaterade till funktionerna i objektet som ska undersökas. Under slutfasen sammanställs ett genomsnittligt beslut baserat på flera träd med hjälp av algoritmer som används för att ta ett slutgiltigt beslut angående objektet.
Modellen är ett bra komplement för den förebyggande säkerheten för slutpunktstplatsen innan körning. En av våra tillämpningar av denna teknik är Cloud ML för Android som används för att upptäcka mobila hot.
Identifiering av liknande hashkoder (platsanpassad hashning)
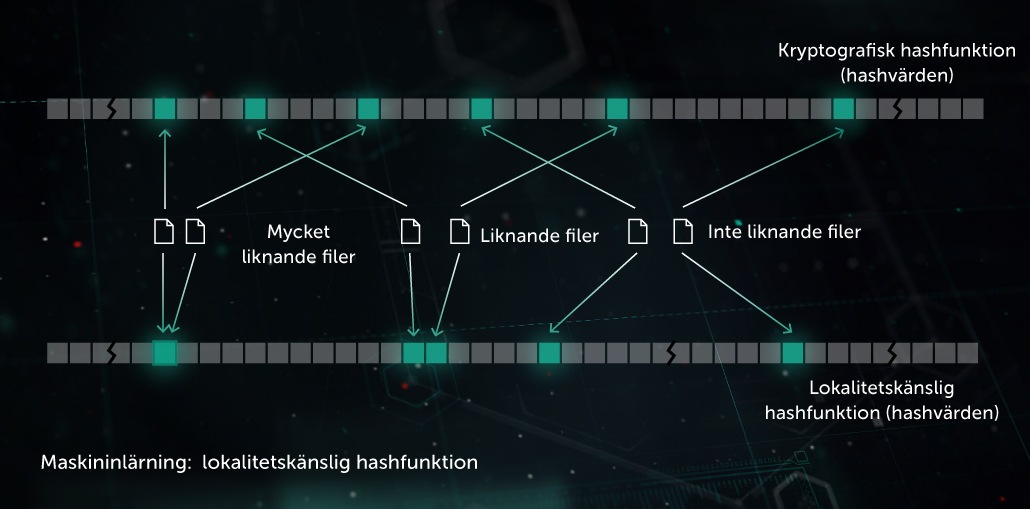
Tidigare var de hashar som användes för att skapa ”fotavtryck” av skadlig programvara känsliga för varje liten ändring i en fil. Denna nackdel utnyttjades av utvecklarna av skadlig programvara som med hjälp av kodförvirringsteknik som polymorfa servrar såg till att mindre ändringar i den skadliga koden inte kunde upptäckas. Identifiering av liknande hashkoder (platsanpassad hashning) är en AI-teknik som används för att identifiera liknande skadliga filer. Tekniken går ut på att hämta filfunktionerna och avgöra de viktigaste med hjälp av vinkelriktad inlärning. En ML-baserad komprimering tillämpas sedan för att omvandla värdena för liknande funktioner till liknande eller identiska mönster. Detta är en bra allmän identifieringsmetod som minskar storleken på identifieringsdatabasen avsevärt i och med att en hel grupp av liknande polymorfa skadliga koder kan identifieras via en enda post.
Modellen är ett bra komplement för den förebyggande säkerheten för slutpunktstplatsen innan körning. Vi använder även tekniken i vårt system för identifiering av liknande hashkoder.
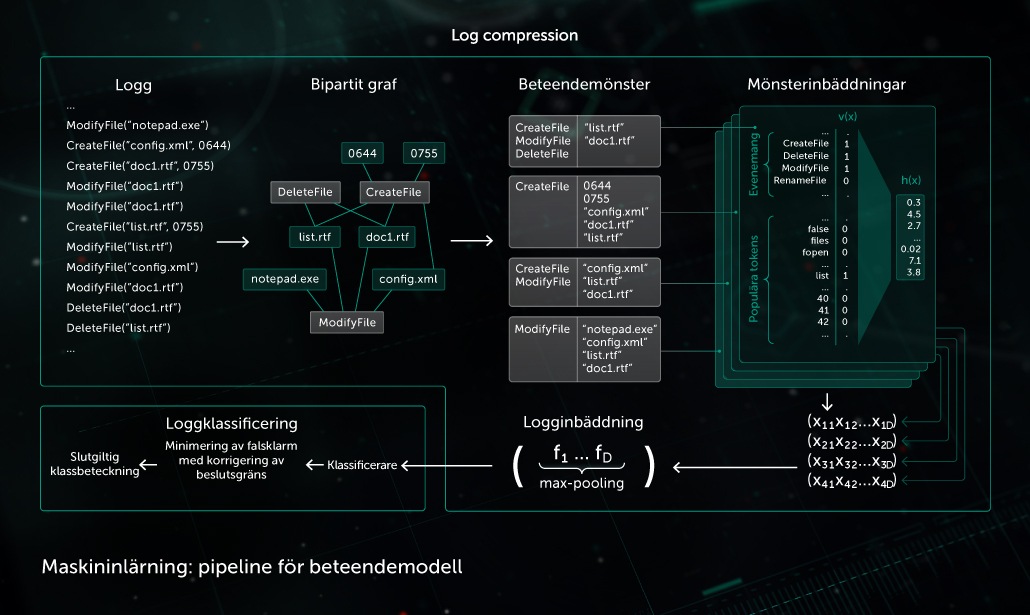
Beteendemodell
Övervakningskomponenterna omfattar en beteendelogg där en sekvens av de systemhändelser som inträffade när processen kördes sammanställs med motsvarande argument. De övervakade data som loggats komprimeras till en händelsesekvens i vår modell för att kunna ange en uppsättning binära vektorer och lära det djupgående, neurala nätverket att urskilja ofarliga loggar från skadliga.
Objektsklassificeringen som tillhandahålls av beteendemodellen används av både statiska och dynamiska identifieringsmoduler i Kasperskys klientsäkerhetsprodukter.
AI spelar också en lika viktig roll när det gäller att bygga upp en lämplig infrastruktur för behandling av skadlig programvara i laboratoriet. Kaspersky använder tekniken för följande infrastruktursändamål:
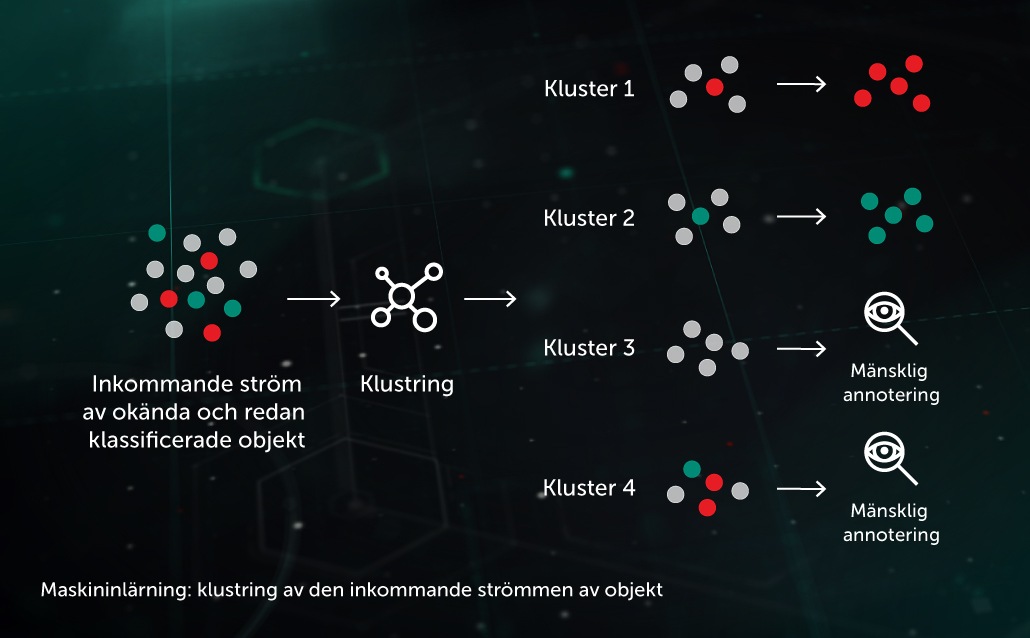
Gruppering (kluster) av inkommande strömningar
Med hjälp av ML-baserade klusteralgoritmer delas det större antalet av okända filer som överförs till infrastrukturen upp i ett mindre antal kluster som är mer lätthanterliga på ett effektivt sätt. Vissa behandlas automatiskt om de innehåller ett redan angivet objekt.
Klassificeringsmodeller för större skalor
Användning av de mest kraftfulla klassificeringsmodellerna (som större skogar baserade på slumpmässiga beslut) kräver ansenliga resurser (processortid, minne) och kostsamma funktionsextraherare. Det behövs till exempel en mer utförlig beteendelogg vid bearbetning inom ett begränsat läge (sandbox). Det är därför mer effektivt att förvara och köra modellerna i labb och sedan ta vara på informationen från besluten som utförs i dessa med hjälp av mindre avancerade och anpassade klassificeringsmodeller.
Säkerhet vid användning av ML-aspekter av AI
Så fort ML-algoritmerna som framställs i labbet släpps ut i verkliga världen är de sårbara för flera typer av attacker som utformats för att tvinga AI-systemen till att göra medvetna fel. Angripare kan smitta en träningsdatauppsättning eller bakåtkompilera modellens kod. Dessutom kan hackare använda råstyrka mot ML-modeller med hjälp av specialutvecklade ”fientliga AI-system” som automatiskt kangenerera flera angreppsprover och skicka dem mot skyddslösningen eller den extraherade ML-modellen tills en svag punkt i modellen upptäcks. Den här typen av attacker kan vara förödande för anti-malwaresystem som använder AI. En felaktigt identifierad trojan kan innebära miljontals smittade enheter och en enorm pengaförlust.
Av denna anledning finns det några viktiga överväganden att göra när man använder AI i säkerhetssystem:
– Leverantören av säkerhetslösningen måste vara medveten om de nödvändiga kraven för AI-elementens prestation i den verkliga och potentiellt farliga världen, och kunna erbjuda en stabil säkerhetslösning som uppfyller dessa krav. ML/AI-specifika säkerhetsrevisioner och ”red-teaming” bör vara nyckelkomponenter i utvecklingen av säkerhetssystem som använder aspekter av AI.
– När du bedömer säkerheten i en lösning som använder AI-element bör du fråga dig i vilken utsträckning lösningen är beroende av data och arkitekturer från tredje part, eftersom många attacker baseras på data från tredje part (då avses flöden med hotinformation, offentliga dataset, förtränade och outsourcade AI-modeller).
– ML/AI-metoder ska inte ses som en patentlösning – de måste ingå i en säkerhetsstrategi med flera lager, där kompletterande skyddstekniker och mänsklig expertis arbetar tillsammans och håller varandra om ryggen.
Det är viktigt att inse att även om Kaspersky har omfattande erfarenhet av effektiv användning av AI-aspekter som ML och underkategorin djupinlärning i sina cybersäkerhetslösningar, så är dessa tekniker inte äkta AI eller AGI (artificiell generell intelligens). Det är fortfarande en lång väg kvar tills maskinerna kan arbeta självständigt och utföra de flesta uppgifter helt på egen hand. Fram till dess kommer nästan alla aspekter av AI inom cybersäkerhet att kräva vägledning och sakkunskap från mänskliga experter för att utveckla och förfina systemen och öka deras kapacitet över tid.
Mer utförlig information om vanligt förekommande attacker på ML/AI-algoritmer och hur du skyddar dig mot dessa finns i faktabladet ”AI under attack – så här skyddar man artificiell intelligens i säkerhetssystem”.

